RAGGY – Bezpieczna Platforma RAG Enterprise

Sztuczna inteligencja w firmach przestaje być eksperymentem – staje się elementem infrastruktury krytycznej. Jednak wraz z jej wdrażaniem pojawiają się pytania o bezpieczeństwo danych, izolację informacji oraz kontrolę nad modelami językowymi. Pojawia się też apetyt, by AI formułując odpowiedzi na zadane pytania korzystała z możliwie szerokiej bazy dokumentów firmowych, ale tym bardziej dostęp do zawartych w nich informacji musi podlegać kontroli.
RAGGY to prywatna, multitenantowa platforma RAG zaprojektowana dla organizacji, które chcą korzystać z AI bez kompromisów w zakresie bezpieczeństwa.
Czym jest RAGGY
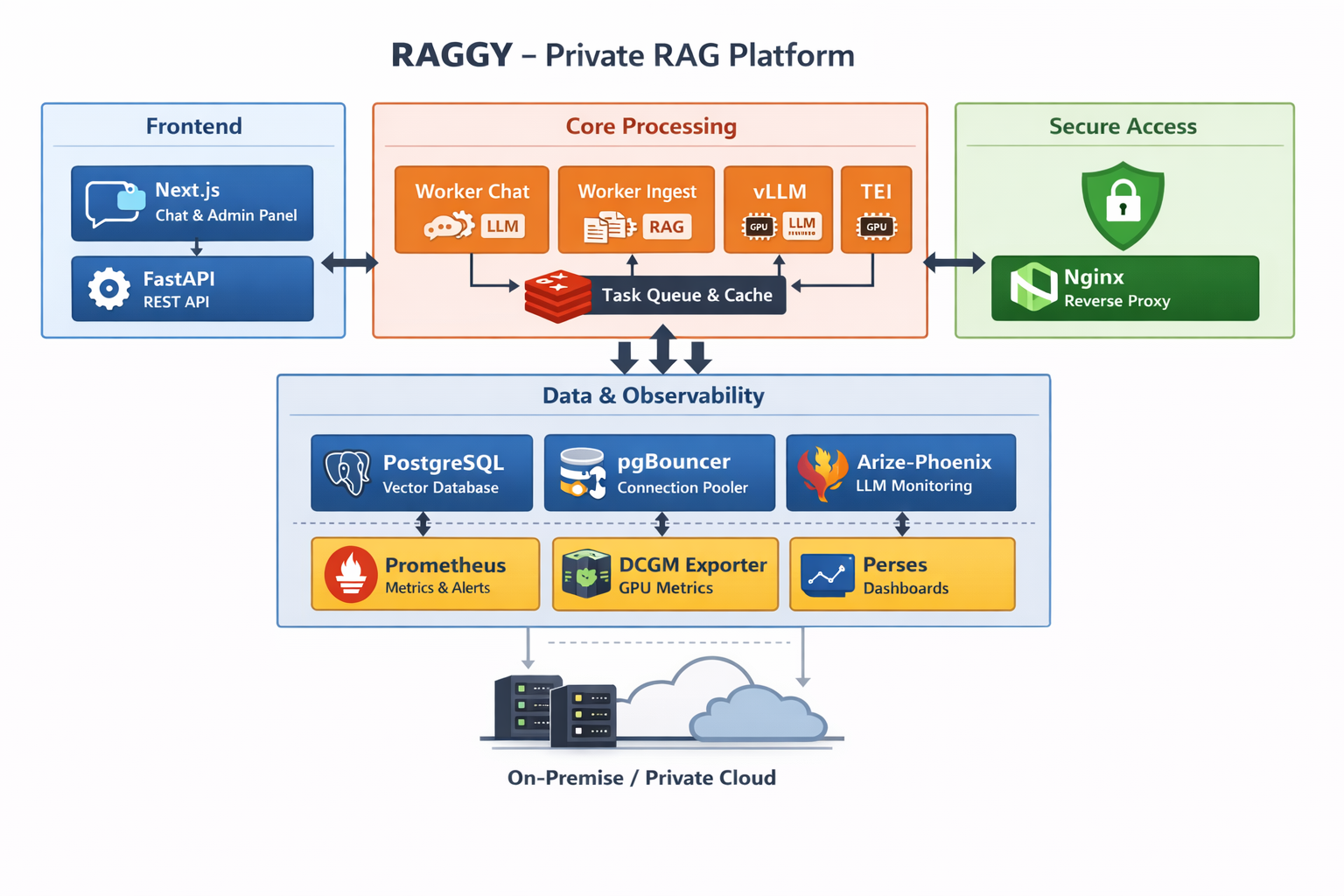
RAGGY to baza wektorowa on-premise dla firm, umożliwiająca lokalne przetwarzanie danych z wykorzystaniem dużych modeli językowych (LLM) oraz embeddingów. System działa w oparciu o architekturę kontenerową (Docker) i może być wdrażany w modelu single-node lub multi-node.
Platforma łączy:
- relacyjną i wektorową bazę danych,
- silniki inferencji LLM,
- silnik embeddingów,
- asynchroniczne workery,
- rozbudowane mechanizmy monitorowania AI.
Kluczowe przewagi RAGGY
Multitenantowość i izolacja danych
RAGGY został zaprojektowany jako system multitenantowy. Oznacza to, że dane poszczególnych działów, jednostek organizacyjnych lub spółek są logicznie izolowane.
Każdy tenant posiada:
- własne repozytoria dokumentów,
- własne embeddingi,
- odseparowany kontekst zapytań AI,
- kontrolę dostępu i role użytkowników.
To rozwiązanie idealne dla dużych organizacji, gdzie bezpieczeństwo i separacja danych są kluczowe.
Rozbudowane observability AI
System generatywny bez monitorowania to ryzyko utraty kontroli nad AI. RAGGY oferuje pełną obserwowalność:
- trace’y zapytań LLM,
- monitoring embeddingów,
- podgląd chunków zwracanych z bazy,
- metryki GPU i wydajności,
- dashboardy operacyjne,
- możliwość testowania promptów.
Dzięki temu IT ma realną kontrolę nad jakością i stabilnością systemu.
Skalowalna architektura kontenerowa
RAGGY składa się z kilkunastu wyspecjalizowanych kontenerów Docker (m.in frontend Next.js, backend FastAPI, PostgreSQL z bazą wektorową, Redis, workery, vLLM, silnik embeddingu oraz warstwa monitoringu).
System może być wdrożony:
- jako single-node – szybkie uruchomienie małych instalacji lub pilota,
- jako multi-node – rozdzielenie warstwy AI, danych i aplikacji w środowisku produkcyjnym.
Pozwala to skalować niezależnie:
- GPU,
- warstwę danych,
- liczbę workerów,
- obsługę użytkowników.
Dlaczego firmy wybierają prywatny RAG
W przeciwieństwie do rozwiązań chmurowych, RAGGY działa w całości lokalnie (on-premise lub private cloud).
To oznacza:
- bezpieczne korzystanie z tysięcy własnych dokumentów,
- brak wysyłania wrażliwych danych do zewnętrznych API,
- zgodność z politykami bezpieczeństwa,
- gotowość do audytu,
- pełną kontrolę nad modelami i embeddingami,
- przewidywalność kosztów infrastruktury,
- centralne zarządzanie regułami systemu.
FAQ - Najczęściej zadawane pytania
1. Czy RAGGY wysyła dane do chmury?
To administrator ustala z jakich modeli korzysta. System może działać w całości lokalnie, bez integracji z zewnętrznymi API.
2. Czy RAGGY nadaje się dla dużych korporacji?
Tak. Architektura multitenantowa umożliwia izolację danych pomiędzy działami i skalowanie infrastruktury.
3. Czy można monitorować działanie modeli AI?
Tak. RAGGY oferuje pełną obserwowalność pracy: od pytania użytkownika, przez selekcję danych z bazy, po sformułowanie odpowiedzi, a do tego metryki, monitoring GPU i dashboardy.
4. Jaki model wdrożenia wybrać?
Single-node sprawdzi się w mniejszych instalacjach, w małych i średnich firmach, w PoC lub w pilotażu dużego rozwiazania. Multi-node wymagane jest w środowisku produkcyjnym z wysoką dostępnością.
5. Jakie są wymagania sprzętowe?
Minimalnie serwer z GPU i 64 GB RAM dla PoC. Produkcyjnie rekomendowane są serwery z 128–256 GB RAM i wydajnymi kartami NVIDIA.